Every time we want to send data from one system to another over network, or to a file, we have to somehow represent it in bytes, this is achieved by data encoding. It's a translation of in-memory objects to byte sequences and vice versa.
This article will present several formats by comparing their performance and considering basic ease of use. Alongside benchmarking the goal is to find a suitable serialization method for my distributed system communication, it should be reasonably fast and must seamlessly integrate between multiple subsystems written in Java, Python and Rust.
Given that applications evolve it's reasonable to assume that our communication will evolve as well, on top of it might not be possible to update all systems at once, and we may be forced to do a rolling-update. For such scenarios it's vital to analyze how schema can evolve. Fortunately for me this is considered a second-tier requirement at the moment - but for anyone interested I suggest taking a look at Martin Kleppmann 'Designing Data-Intensive Applications' chapter 4, or his excellent post about it.
Methodology
I'm going to compare simple scenarios like serialization, deserialization and sometimes special combinations using provided Java clients for each respective format.
Micro-benchmarking is notoriously tricky to get right, and even when we get it right it's hard to draw correct conclusions. On top of that, I'm using a JVM-based language that makes it even worse. Profiling is a must, even with these simple benchmarks I had to profile the code to weed out quite a few obvious problems.
It's turns out it's crucial to use data that is as close to production data as possible, for benchmarking I used a message schema that is fairly representative for my use-case - but schema can make significant difference. Additionally, performance will vary depending not only on how you use the client but also what client is used (i.e. Java Avro client vs C++ Avro client etc.)
Note that the purpose of this benchmark is to compare serialization/deserialization speed, this means that these values probably don't represent 'optimal' speed that could be achieved - there are potential optimizations that could be applied like: avoid autoboxing, using alternative client/approach, using more judicious types (do we really need an int for a version field?) etc. Unfortunately it means that this might be unfair for some formats, especially those that allow for more fine-grained control. On the other hand, it's probably better to measure the most likely usage instead of trying to hyper-tune everything - to see where hyper optimization may lead, see Benchmarks Game source codes. I tried my best to balance fairness with 'typical usage'.
Last but not least, the code for these benchmarks is available here. Improvement suggestions highly appreciated.
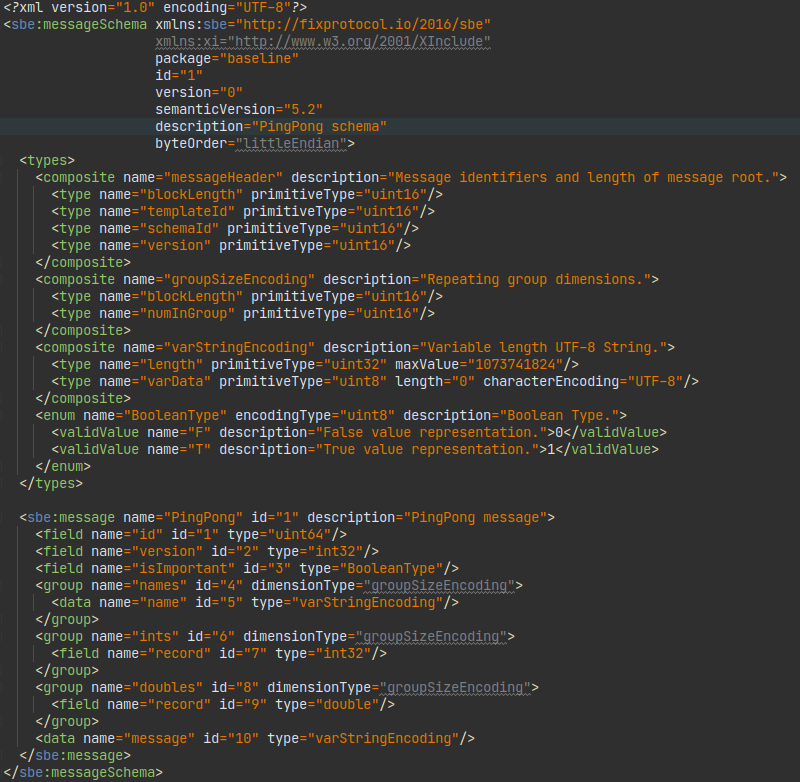
Protobuf schema:
message PingPong {
int64 id = 1; // 1
int32 version = 2; // 2
string message = 3; // "Random message - " + System.currentTimeMillis()
bool is_important = 4; // true
repeated string names = 5; // ["John-1", "John-1", "John-2"]
repeated int32 ints = 6; // [1, 22, 333, 4444, 55555]
repeated double doubles = 7; // [1.132314, 2.111111, 3.314155, 4.1231488, 5.12395832]
}
Other formats have equivalent/similar schemas, for details see code.
Benchmarks
Let's cut to the chase, on my desktop (Ryzen 3900x): throughput - more is better, ± stands for confidence interval (at 99.9%):
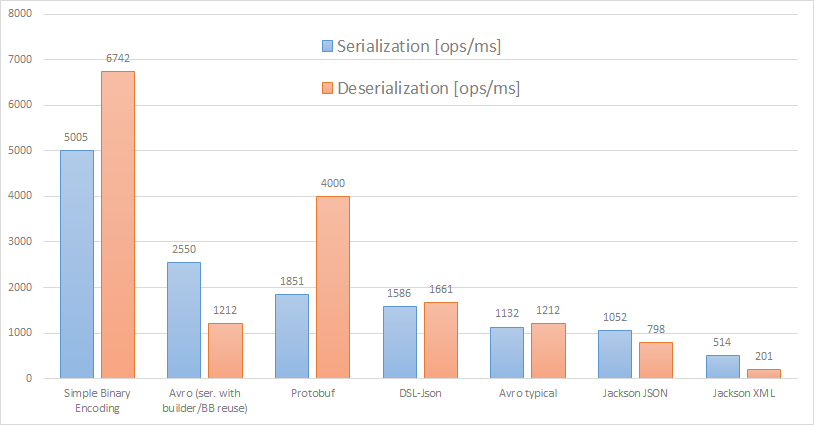
Tabular:

There are a few surprises, the first one is relatively poor performance for the default Avro client usage, results are almost on par with typical JSON read/write speed. I definitely expected better.
For Avro serialization I also provide slightly more optimized version while I'm not doing the same for deserialization. For a typical user I consider it to be a little too error-prone to operate on a single mutable object/ByteBuffer post deserialization, especially when it's not advised as 'the standard approach'. Eventually, it can perform quite well during serialization, see 'Why benchmarking is tricky part 1' below for details.
The format itself is only partially responsible for speed, it sets a theoretical upper limit. Typical JSON serialization as done in Jackson (via reflection) has very polished user experience but performs rather poorly. Surprisingly, DSL-Json shows how much can be achieved by a better faster implementation. I have to admit that this lets-generate-classes-during-compilation approach turned out to be quite seamless and performance improvements - 50% higher throughput in serialization and twice as fast during reading - are impressive.
DSL-Json is a strong contender when external systems enforce JSON usage.
Payload size is the smallest for Protobuf, that's reasonable given that the padding doesn't take space. The other side of spectrum is taken by textual formats, this is especially pronounced when a schema is heavily skewed towards numeric data.
Simple binary encoding
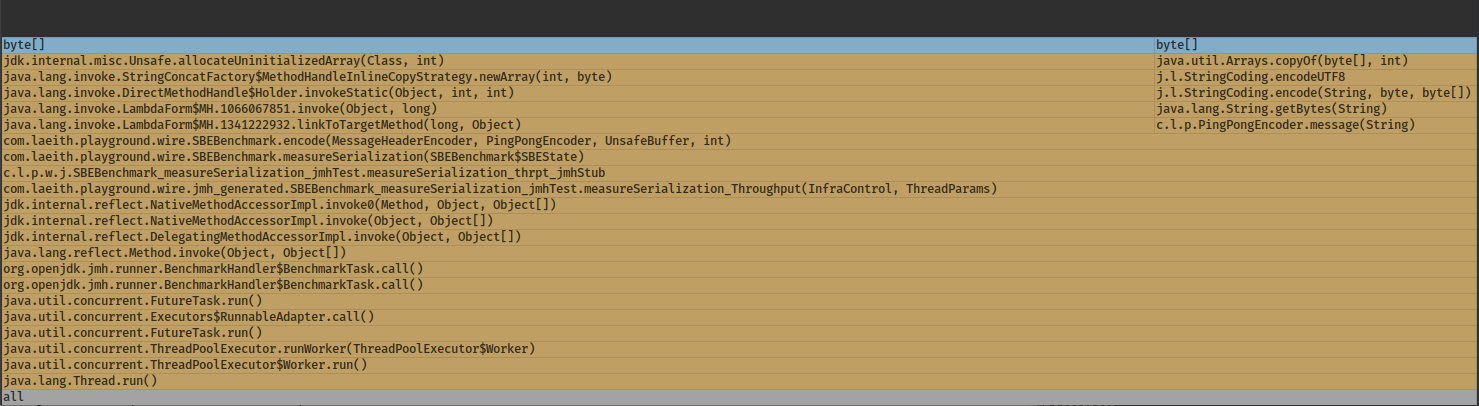
SBE requires a separate paragraph on its own. The format uses a very interesting "zero-copy" approach which gives the best speed results by far. This gives not only the best throughput but also the lowest latency (not measured in this particular benchmark). Zero-copy means that it tries to avoid costly encode/decode steps and reuse pre-allocated objects/buffers.
SBE allocation graph:
Protobuf allocations for comparison:
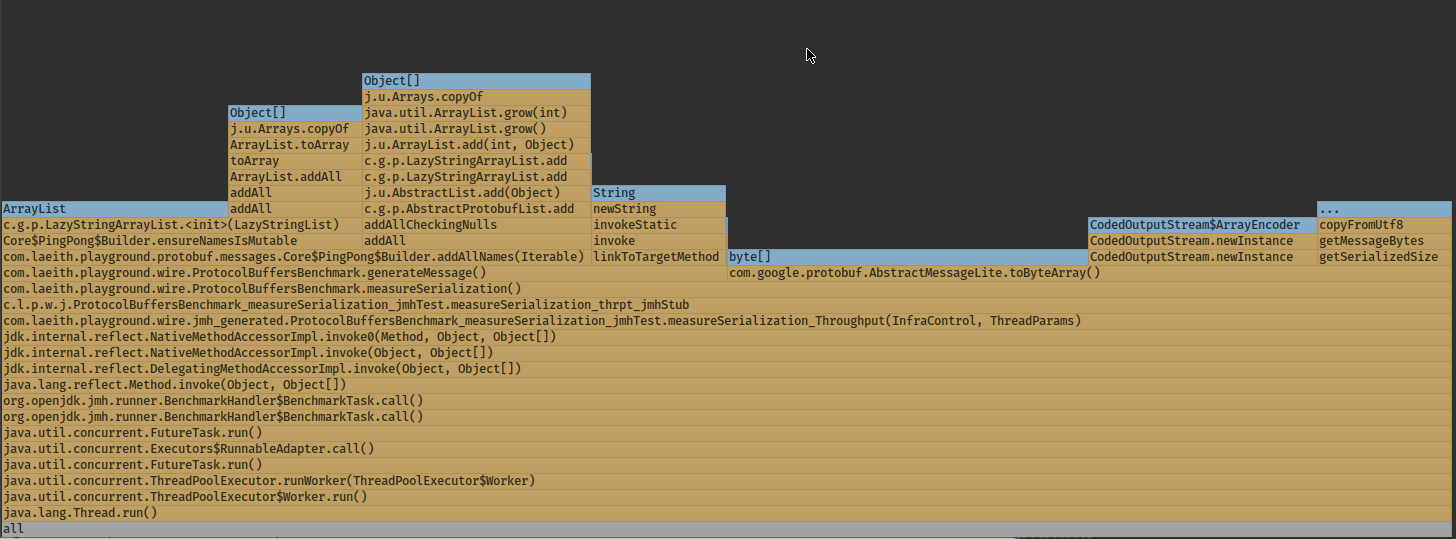
Provided that we can make full use of that and don't do any unnecessary copying in the business logic (and apply a few more performance tricks) it's possible to achieve outstanding results, all on a single pinned thread.
Unfortunately this comes at a price of usability: schema is very extensive and verbose, reading/writing requires operating on Bytes/Buffers semi-directly, and the marriage with business logic is also quite cumbersome. At least infamous XML has good tooling/IDE support out of the box. I'd say it might be a reasonable price to pay if speed is the dominant requirement and we have lots of time.
There are other "zero-copy" formats like Cap'n Proto and FlatBuffers, maybe these are slightly more user-friendly. Though, it's not obvious how to make it more convenient without sacrificing performance.
Why benchmarking is tricky part 1: Client usage
Even a single client can be used in multiple ways, this is especially acute in case of Avro where the naive usage provides speeds on par with JSON, but two relatively minor changes can give us 2.5x improvement:
'Typical/pure' Avro serialization usage: 1132 ± 27 ops/ms
When we take a look at CPU flame graph it becomes obvious what's the problem:
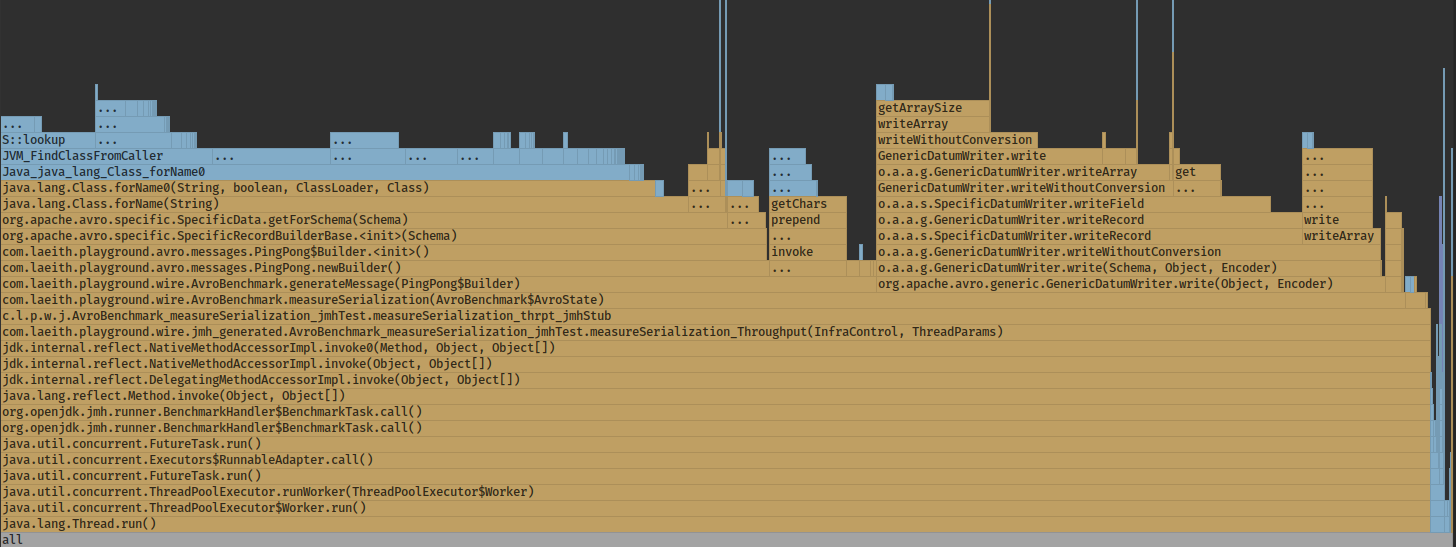
In the naive implementation we spend half the time for builders recreation on each pass. Results after introducing message builder and bytebuffer reuse:
Avro serialization with optimizations: 2550 ± 109 ops/ms
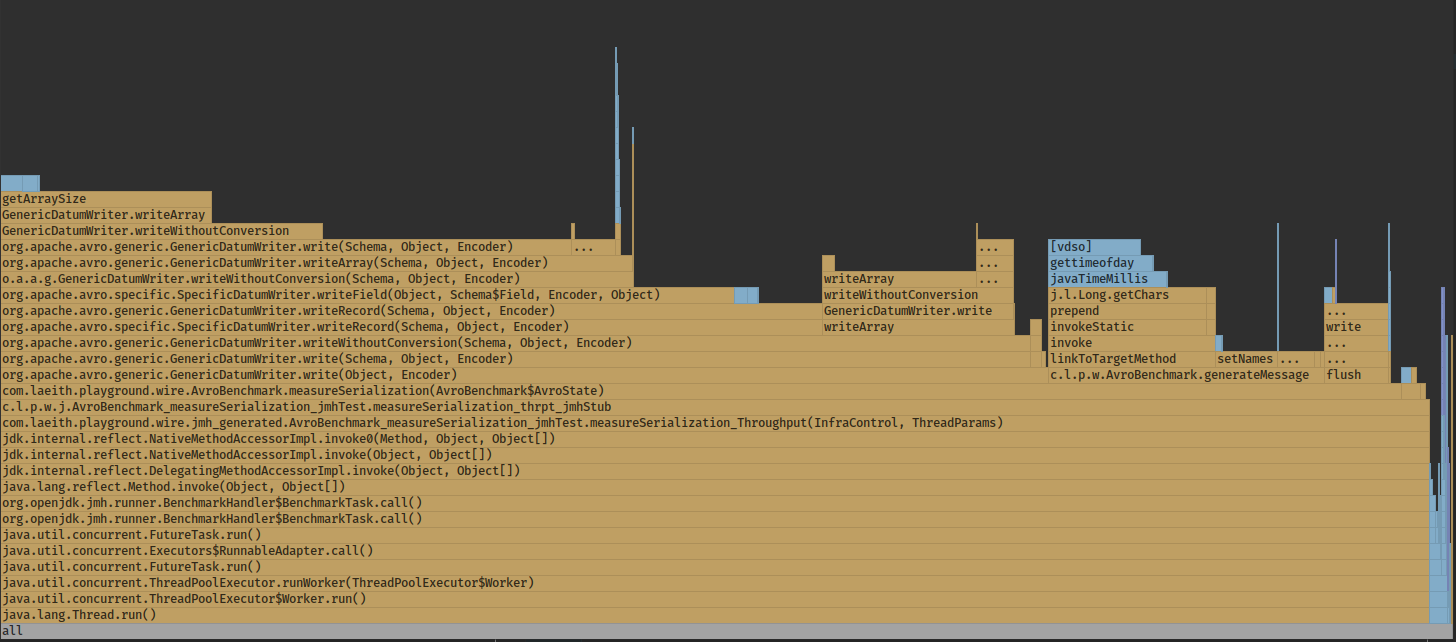
Much better. Interestingly, reusing builders in Protobuf Java implementation is counterproductive and yields similar performance results.
That's one of the reasons benchmarking on your own is important, even if someone achieves poor results in their application it doesn't mean that you must suffer the same fate in your system.
Why benchmarking is tricky part 2: Schema impact
Assuming we get reasonably reliable results it's still not so easy to apply it in real world. Let's say that we use the abovementioned benchmarks to guide our choices, let's say that for our requirements Protobuf is too slow. In practice, it turns out that most or all of our data is represented by doubles, if we do the benchmark we get:
message DoublesMsg {
double double1 = 1; // 1.1234567899
double double2 = 2; // 2.1234567899
double double3 = 3; // 3.1234567899
double double4 = 4; // 4.1234567899
double double5 = 5; // 5.1234567899
repeated double doubles = 6; // [1.132314, 2.111111, 3.314155, 4.1231488, 5.12395832]
}

Explanation for enormous speed up for Protobuf, and lack of any change for JSON is probably obvious for an attentive engineer. Logic behind this is left as an exercise for the reader.
Hint, benchmarks with comparable string-only data size when serialized to JSON:

Micro-benchmarking, is it worth it?
All problems with doing such micro-benchmarks make me wonder how much value they provide. I guess they are a good hint at what can potentially perform well, nonetheless I believe that doing a production-like end-to-end performance testing is necessary anyway - it's far too easy to make a small mistake in business logic that completely trumps any gains from faster serialization framework.
Benchmarking, especially comparison when we aren't experts in a given technology, is hard: usually it's advised to write two versions alongside and check differences, but even in only slightly more complex scenarios writing two same versions might be a non-obvious task.
In the end, does it really make any difference? Well, for high frequency trading it can be of paramount importance when end-to-end processing time is typically measured in microseconds (even 10s of microseconds - without using FPGAs/ASICs). On the other hand, if business logic takes milliseconds, or it does disk I/O, or it makes external calls, then serialization time might be on par with measurement error.
Having spent a few days toying with different formats and clients I settled with Protobuf. I was tempted to give SBE a try hoping that I could come up with a seamless abstraction over the client - but it doesn't seem to have good clients outside of Java and C++. Protobuf definitely isn't the fastest, but it seems to provide a good balance between performance and usability/time-to-market. On top of that, due to its ubiquity it's almost as easy to find performant clients in any language as it is for JSON.
In the future it might be useful to extend my benchmarks to measure performance per payload size, after all serialization/deserialization might not scale linearly i.e. due to implementation details.